




I always like to explain caching with an analogy…
think in a book store where there are two floors the first floor has some attendants and the second floor has books that are available to be sold.
Every time that one client arrives at the store and asks for a book, one of the attendants needs to go upstairs and search for the book in order to deliver it for the customer.
Thinking in a web server it's the same that receiving a request, accessing the database to get data, and sending a response for the customer.
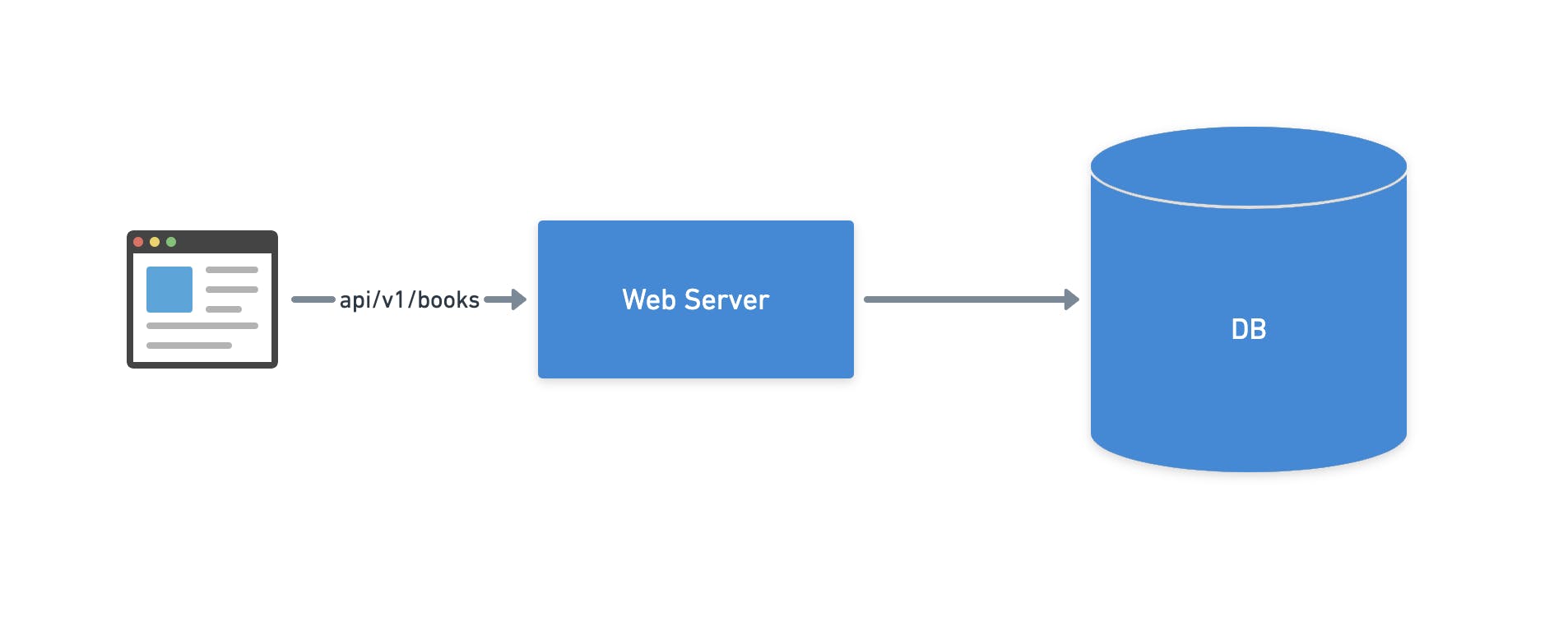
One way to make the lives of the attendants more easily is adding a shelf on the first floor with the most asked books.
With the most asked books on the first floor, the attends don't need to waste time going upstairs and searching for those books all the time.
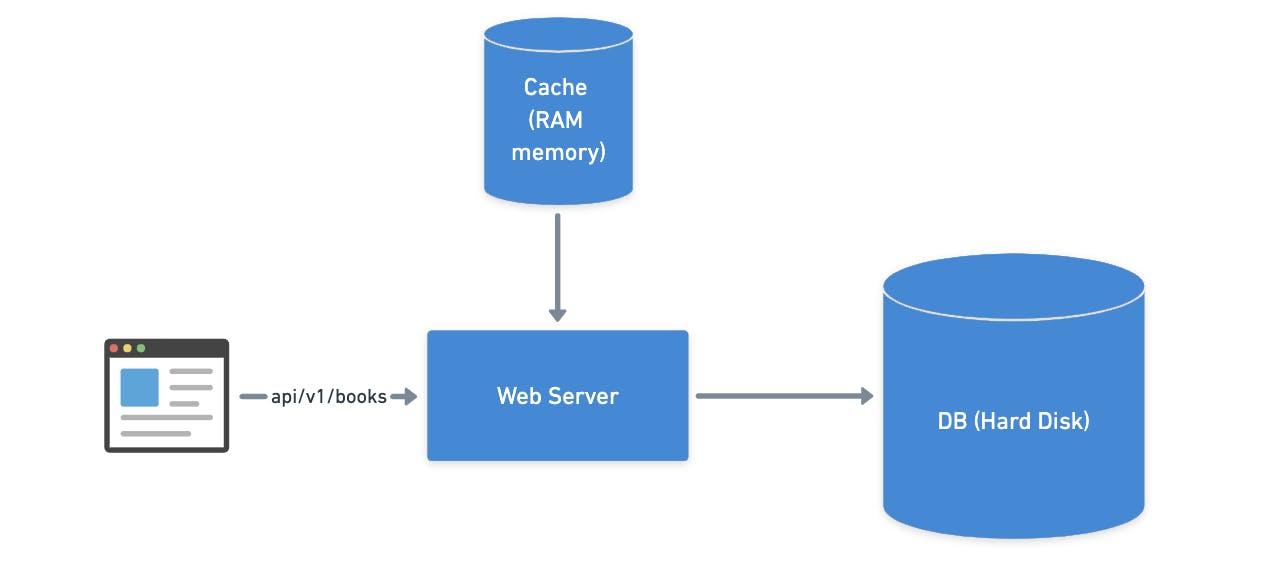
This is the idea behind caching, get a set of data most used and add that in a faster memory (RAM memory) or move it geographically near to the customers, to decrease the latency and delivery the data faster.
Why not use cache for everything?
You should be thinking right now, cache looks so good, so why do not use that to store all the data from my application?
There are two problems with that, the first problem is cost, RAM memory is way more expensive than hard disc memory, the second problem is that the data in RAM memory just will be there during the runtime, which means if the server is restarted all the data on cache will be lost.
So generally cache just holds replicated data from the main data store, and just the most frequently requested data. It will make your system perform better in most cases.
Types of cache
There are several strategies that you can use to build a cache, the business and the application architecture will be strong influencers to decide which will fit better for the use case.
Application server cache
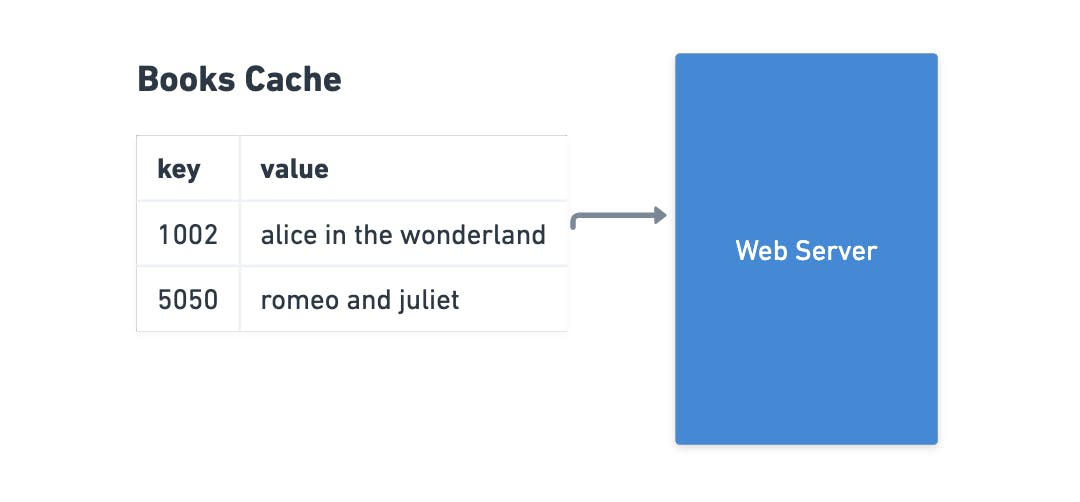
One of the easiest ways to add cache is putting that directly on your server, generally using a hash map data struct where you can take advantage to store data locally based on a key, the idea here is always hit the caching before going to the main memory store, avoiding unnecessary processing.
The disadvantage of this approach comes when a server is scaled horizontally, in this type of scaling you can have several instances of the same services running, which leads to cache misses (not finding the data inside the cache) given that each machine has its own cache.
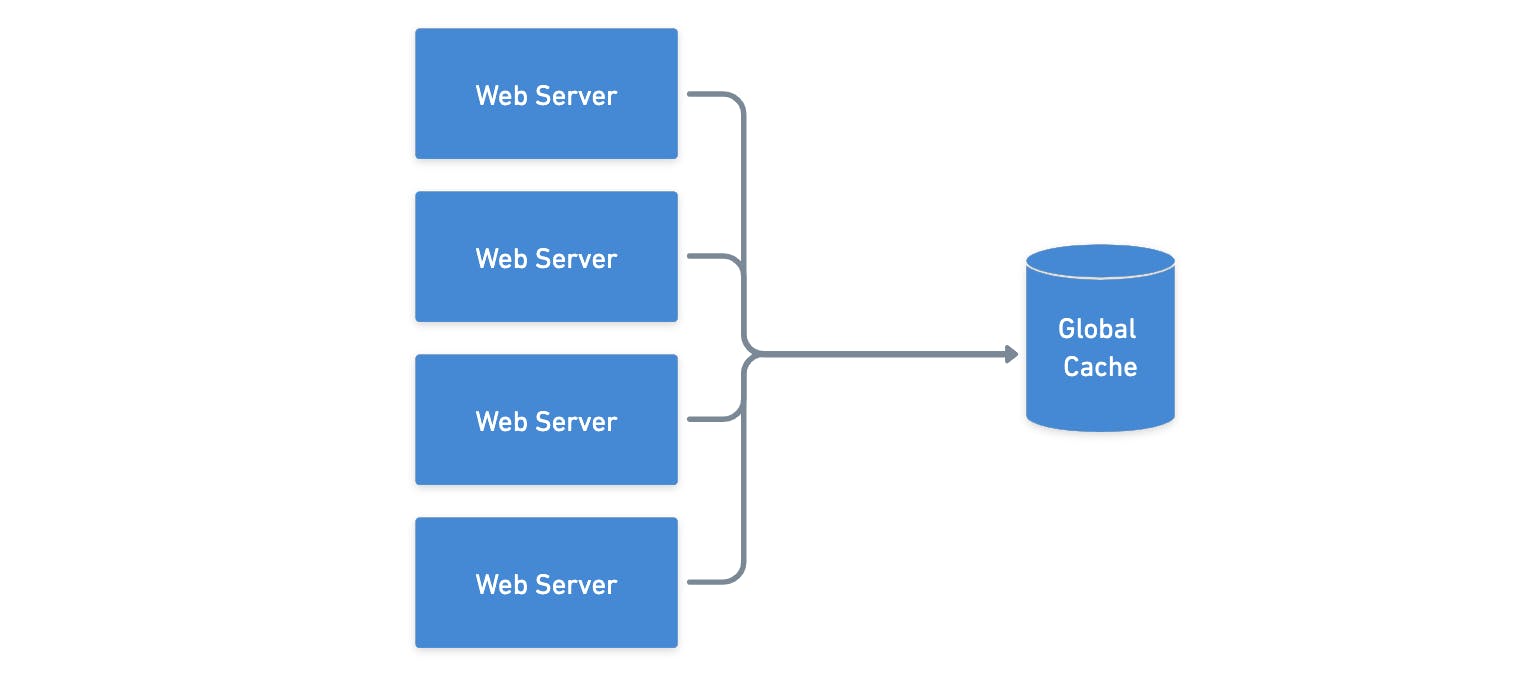
Global cache
For this strategy the cache will be a part of the server running in a different machine, with that, one or many server instances can access the same cache avoiding cache misses for most of the cases.
However, as the number of clients and requests increases, this global cache can be overwhelmed and lead to failures.
There are two ways to deal with cache miss on global cache:
- The global cache can be responsible to identify the miss and request the data from the main datastore
- The server that received the request can identify the cache miss and update the cache with the data from the main data store.
Distributed cache
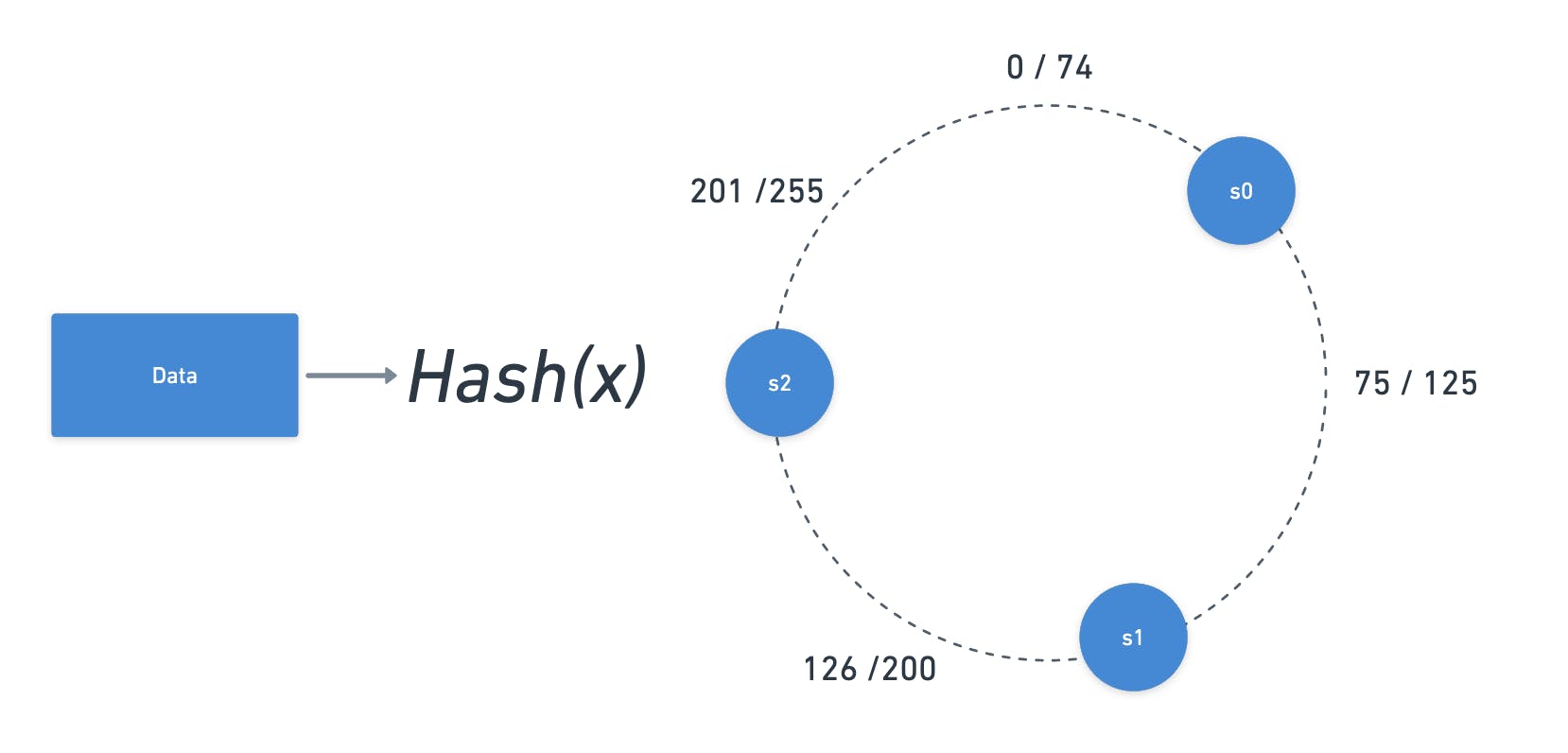
Here the cache is split into many instances using a consistent hashing function and each of these instances will own part of the cache data. those instances are placed in a conceptual clockwise ring where the instance can be found by the hash.
Let's use an example basead on the image bellow, on this image there is a ring with numbers from 0 to 255 and multiple cache instances were distribuided around this ring in different positions, also there is a hashing function that generates numbers from 0 to 255 based in some key.
Thinking in a case where a web server received a request, the server may use the key from this request plus the hash function to generate a number, let assume that for this example the number generate was 80, so to indentify which cache server should be used the algorithm just needs to move clockwise until find a server, for the number 80 the server would be s1.
Content Delivery Network (CDN)
Think in an application where the assets are very important for the business as Instagram for example that has a huge amount of images been uploaded every day, now think that the main server of Instagram is located in San Francisco hypothetically.
For people who live in San Francisco or near this city will get the content very quickly, beacause fiscally the asset will transverse just a short path in the network, but for people from other countries as for example japan they will need to wait a “long” period of time to receive this asset.
This is when CDN comes in, basically, the idea is to have servers near from the people, so once that assert is requested a copy will be stored at these servers and will be delivered a lot faster on the next time.
Cache write policies
There is two main policies when we thinking about write data in a cache.
- Write-through policy
- Write-back policy
Write-through policy
On this police when the cache is updated with new data, the main data source is also updated together, it makes the data source and the cache be always consistent.
the disadvantage of this approach is the access to the main data source, where in several cases can slow down the process.
Write-back policy
For the write-back policy, the cache will be always updated first and a flag will be added to the cache as an indication that the data has changed.
To make the data synchronized a process will run from time to time updating the data in the main data source.
This approach makes the process a lot more quickly but also makes the data inconsistent during some time and can cause a miss of data if the cache machine stop to work
Cache Eviction Policies
There are many evictions policies that could be used in order to free cache space.
First In First Out (FIFO): It will work in the same that a Queue where the first data that was added also will be the first data to leave from the cache.
Last In First Out (LIFO): same as a Stack the last data added will be the first data to leave from the cache.
Least Recently Used (LRU): One of the most used policies where the least recently used item will be discarded first.
Most Recently Used (MRU): This is the opposite of LRU where the item most recently used will be discarded first.
Least Frequently Used (LFU): LFU policy makes usage of a counter to determine how often an item was needed and discard the less often used, the difference between LRU and LFU is that LRU makes the usage of time to determine if a data need to be released and LFU makes the usage of a counter.
Random Replacement (RR): Removes an item Randomly when cache space is needed.
Example
If you looking for an example of caching I created this one to illustrate a very common case where the cache can bring a huge benefit.
If would like to see more content about software development and architecture, follow me ✌🏻
Thanks for reading!